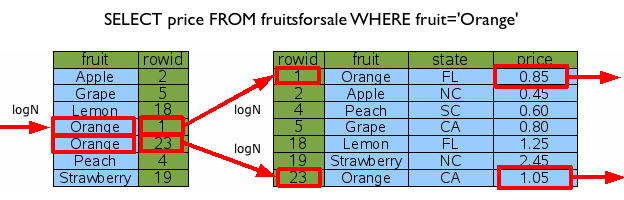
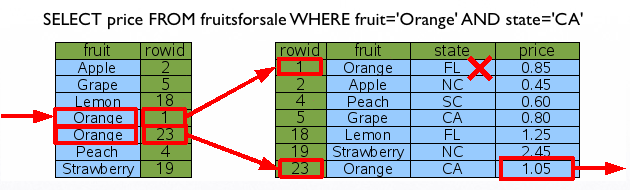
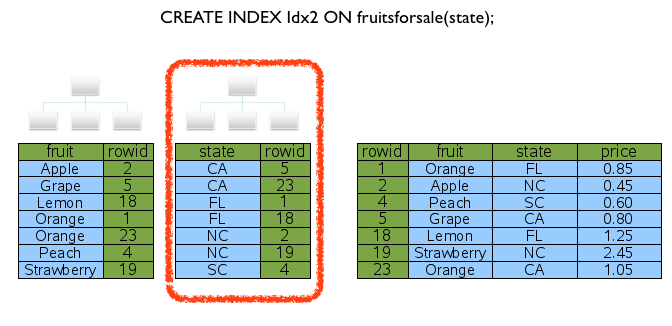
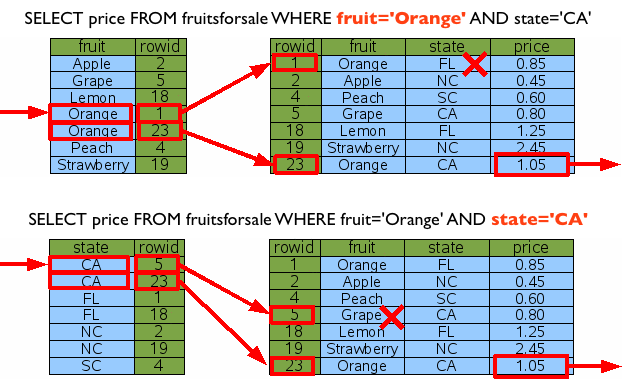
1. 절차형 SQL 개요
일반적인 개발 언어처럼 SQL에도 절차 지향적인 프로그램이 가능하도록 DBMS 벤더별로 PL(Procedural Language)/SQL(Oracle), SQL/PL(DB2), T-SQL(SQL Server) 등의 절차형 SQL을 제공하고 있다. 절차형 SQL을 이용하면 SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈을 생성할 수 있다. 본 절에서는 절차형 SQL을 이용하여 만들 수 있는 저장 모듈인 Procedure, User Defined Function, Trigger에 대해서 간단하게 살펴본다. (상세한 내역은 각 DBMS 벤더의 매뉴얼을 참조한다.)
2. PL/SQL 개요
가. PL/SQL 특징
Oracle의 PL/SQL은 Block 구조로 되어있고 Block 내에는 DML 문장과 QUERY 문장, 그리고 절차형 언어(IF, LOOP) 등을 사용할 수 있으며, 절차적 프로그래밍을 가능하게 하는 트랜잭션 언어이다. 이런 PL/SQL을 이용하여 다양한 저장 모듈(Stored Module)을 개발할 수 있다. 저장 모듈이란 PL/SQL 문장을 데이터베이스 서버에 저장하여 사용자와 애플리케이션 사이에서 공유할 수 있도록 만든 일종의 SQL 컴포넌트 프로그램이며, 독립적으로 실행되거나 다른 프로그램으로부터 실행될 수 있는 완전한 실행 프로그램이다. Oracle의 저장 모듈에는 Procedure, User Defined Function, Trigger가 있다.
PL/SQL의 특징은 다음과 같다.
- PL/SQL은 Block 구조로 되어있어 각 기능별로 모듈화가 가능하다. - 변수, 상수 등을 선언하여 SQL 문장 간 값을 교환한다. - IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능하도록 한다. - DBMS 정의 에러나 사용자 정의 에러를 정의하여 사용할 수 있다. - PL/SQL은 Oracle에 내장되어 있으므로 Oracle과 PL/SQL을 지원하는 어떤 서버로도 프로그램을 옮길 수 있다. - PL/SQL은 응용 프로그램의 성능을 향상시킨다. - PL/SQL은 여러 SQL 문장을 Block으로 묶고 한 번에 Block 전부를 서버로 보내기 때문에 통신량을 줄일 수 있다.
[그림 Ⅱ-2-18]은 PL/SQL Architecture이다. PL/SQL Block 프로그램을 입력받으면 SQL 문장과 프로그램 문장을 구분하여 처리한다. 즉 프로그램 문장은 PL/SQL 엔진이 처리하고 SQL 문장은 Oracle 서버의 SQL Statement Executor가 실행하도록 작업을 분리하여 처리한다.

나. PL/SQL 구조
다음은 PL/SQL의 블록 구조를 표현한 내용이다.

- DECLARE : BEGIN ~ END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입을 선언하는 선언부이다. - BEGIN ~ END : 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용하여 필요한 로직을 처리하는 실행부이다. - EXCEPTION : BEGIN ~ END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할 것이지를 정의하는 예외 처리부이다.
다. PL/SQL 기본 문법(Syntax)
앞으로 살펴볼 User Defined Function이나 Trigger의 생성 방법이나 사용 목적은 다르지만 기본적인 문법은 비슷하기 때문에 여기에서는 Stored Procedure를 통해서 PL/SQL에 대한 기본적인 문법을 정리한다.
CREATE [OR REPLACE] Procedure [Procedure_name] ( argument1 [mode] data_type1, argument2 [mode] date_type2, ... ... ) IS [AS] ... ... BEGIN ... ... EXCEPTION ... ... END; /
다음은 생성된 프로시저를 삭제하는 명령어이다.
DROP Procedure [Procedure_name];
CREATE TABLE 명령어로 테이블을 생성하듯 CREATE 명령어로 데이터베이스 내에 프로시저를 생성할 수 있다. 이렇게 생성한 프로시저는 데이터베이스 내에 저장된다. 프로시저는 개발자가 자주 실행해야 하는 로직을 절차적인 언어를 이용하여 작성한 프로그램 모듈이기 때문에 필요할 때 호출하여 실행할 수 있다. [OR REPLACE] 절은 데이터베이스 내에 같은 이름의 프로시저가 있을 경우, 기존의 프로시저를 무시하고 새로운 내용으로 덮어쓰기 하겠다는 의미이다. Argument는 프로시저가 호출될 때 프로시저 안으로 어떤 값이 들어오거나 혹은 프로시저에서 처리한 결과값을 운영 체제로 리턴시킬 매개 변수를 지정할 때 사용한다. [mode] 부분에 지정할 수 있는 매개 변수의 유형은 3가지가 있다. 먼저 IN은 운영 체제에서 프로시저로 전달될 변수의 MODE이고, OUT은 프로시저에서 처리된 결과가 운영체제로 전달되는 MODE이다. 마지막으로 잘 쓰지는 않지만 INOUT MODE가 있는데 이 MODE는 IN과 OUT 두 가지의 기능을 동시에 수행하는 MODE이다. 마지막에 있는 슬래쉬(“/”)는 데이터베이스에게 프로시저를 컴파일하라는 명령어이다. 앞에서 잠깐 언급했지만 PL/SQL과 관련된 내용은 상당히 다양하고 분량이 많기 때문에 본 가이드에서는 간단한 문법과 사용 목적에 초점을 맞춰 이해하기 바란다.
3. T-SQL 개요
가. T-SQL 특징
T-SQL은 근본적으로 SQL Server를 제어하기 위한 언어로서, T-SQL은 엄격히 말하면, MS사에서 ANSI/ISO 표준의 SQL에 약간의 기능을 더 추가해 보완적으로 만든 것이다. T-SQL을 이용하여 다양한 저장 모듈(Stored Module)을 개발할 수 있는데, T-SQL의 프로그래밍 기능은 아래와 같다.
- 변수 선언 기능 @@이라는 전역변수(시스템 함수)와 @이라는 지역변수가 있다. - 지역변수는 사용자가 자신의 연결 시간 동안만 사용하기 위해 만들어지는 변수이며 전역변수는 이미 SQL서버에 내장된 값이다. - 데이터 유형(Data Type)을 제공한다. 즉 int, float, varchar 등의 자료형을 의미한다. - 연산자(Operator) 산술연산자( +, -, *, /)와 비교연산자(=, <, >, <>) 논리연산자(and, or, not) 사용이 가능하다. - 흐름 제어 기능 IF-ELSE와 WHILE, CASE-THEN 사용이 가능하다. - 주석 기능한줄 주석 : -- 뒤의 내용은 주석범위 주석 : /* 내용 */ 형태를 사용하며, 여러 줄도 가능함
T-SQL과 타 DBMS가 제공하는 SQL은 약간만 다를 뿐 그 맥락은 같이 하기 때문에, 조금의 변경 사항만 적용하면 같은 기능을 수행할 수 있다. 그리고 많은 사람들이 SQL 서버에 엔터프라이즈 매니저의 UI를 통하여 접근하는 경우가 많은데, 실??이 더 바람직하다.
나. T-SQL 구조
다음은 T-SQL의 구조를 표현한 내용이다. PL/SQL과 유사하다.

- DECLARE : BEGIN ~ END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입을 선언하는 선언부이다. - BEGIN ~ END : 개발자가 처리하고자 하는 SQL문과 여러 가지 비교문, 제어문을 이용하여 필요한 로직을 처리하는 실행부이다. T-SQL에서는 BEGIN, END 문을 반드시 사용해야하는 것은 아니지만 블록 단위로 처리하고자 할 때는 반드시 작성해야 한다. - ERROR 처리 : BEGIN ~ END 절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할 것이지를 정의하는 예외 처리부이다.
다. T-SQL 기본 문법(Syntax)
앞으로 살펴볼 User Defined Function이나 Trigger의 생성 방법과 사용 목적은 Stored Procedure와 다르지만 기본적인 문법은 비슷하기 때문에 여기에서는 Stored Procedure를 통해서 T-SQL에 대한 기본적인 문법을 정리한다.
CREATE Procedure [schema_name.]Procedure_name @parameter1 data_type1 [mode], @parameter2 date_type2 [mode], ... ... WITH
AS ... ... BEGIN ... ... ERROR 처리 ... ... END;다음은 생성된 프로시저를 삭제하는 명령어이다.
DROP Procedure [schema_name.]Procedure_name;
CREATE TABLE 명령어로 테이블을 생성하듯 CREATE 명령어로 데이터베이스 내에 프로시저를 생성할 수 있다. 이렇게 생성한 프로시저는 데이터베이스 내에 저장된다. 프로시저는 개발자가 자주 실행해야 하는 로직을 절차적인 언어를 이용하여 작성한 프로그램 모듈이기 때문에 필요할 때 호출하여 실행할 수 있다. 프로시저의 변경이 필요할 경우 Oracle은 [CREATE OR REPLACE]와 같이 하나의 구문으로 처리하지만 SQL Server는 CREATE 구문을 ALTER 구문으로 변경하여야 한다. @parameter는 프로시저가 호출될 때 프로시저 안으로 어떤 값이 들어오거나 혹은 프로시저에서 처리한 결과 값을 리턴 시킬 매개 변수를 지정할 때 사용한다. [mode] 부분에 지정할 수 있는 매개 변수(@parameter)의 유형은 4가지가 있다.
① VARYING결과 집합이 출력 매개 변수로 사용되도록 지정합니다. CURSOR 매개변수에만 적용된다. ② DEFAULT지정된 매개변수가 프로시저를 호출할 당시 지정되지 않을 경우 지정된 기본값으로 처리한다. 즉, 기본 값이 지정되어 있으면 해당 매개 변수를 지정하지 않아도 프로시저가 지정된 기본 값으로 정상적으로 수행이 된다. ③ OUT, OUTPUT프로시저에서 처리된 결과 값을 EXECUTE 문 호출 시 반환한다. ④ READONLY자주 사용되지는 않는다. 프로시저 본문 내에서 매개 변수를 업데이트하거나 수정할 수 없음을 나타낸다. 매개 변수 유형이 사용자 정의 테이블 형식인 경우 READONLY를 지정해야 한다.
WITH 부분에 지정할 수 있는 옵션은 3가지가 있다.
① RECOMPILE데이터베이스 엔진에서 현재 프로시저의 계획을 캐시하지 않고 프로시저가 런타임에 컴파일 된다. 데이터베이스 엔진에서 저장 프로시저 안에 있는 개별 쿼리에 대한 계획을 삭제하려 할 때 RECOMPILE 쿼리 힌트를 사용한다. ② ENCRYPTIONCREATE PROCEDURE 문의 원본 텍스트가 알아보기 어려운 형식으로 변환된다. 변조된 출력은 SQL Server의 카탈로그 뷰 어디에서도 직접 표시되지 않는다. 원본을 볼 수 있는 방법이 없기 때문에 반드시 원본은 백업을 해두어야 한다. ③ EXECUTE AS 해당 저장 프로시저를 실행할 보안 컨텍스트를 지정한다.
앞에서 잠깐 언급했지만 T-SQL과 관련된 내용은 상당히 다양하고 분량이 많기 때문에 본 가이드에서는 간단한 문법과 사용 목적에 초점을 맞춰 이해하기 바란다.
4. Procedure의 생성과 활용
[그림 Ⅱ-2-21]은 앞으로 생성할 Procedure의 기능을 Flow Chart로 나타낸 그림이다.

[예제] SCOTT 유저가 소유하고 있는 DEPT 테이블에 새로운 부서를 등록하는 Procedure를 작성한다. SCOTT 유저가 기본적으로 소유한 DEPT 테이블의 구조는 [표 Ⅱ-2-14]와 같다.

[예제] Oracle CREATE OR REPLACE Procedure p_DEPT_insert -------------① ( v_DEPTNO in number, v_dname in varchar2, v_loc in varchar2, v_result out varchar2) IS cnt number := 0; BEGIN SELECT COUNT(*) INTO CNT -------------② FROM DEPT WHERE DEPTNO = v_DEPTNO AND ROWNUM = 1; if cnt > 0 then -------------③ v_result := '이미 등록된 부서번호이다'; else INSERT INTO DEPT (DEPTNO, DNAME, LOC) -------------④ VALUES (v_DEPTNO, v_dname, v_loc); COMMIT; -------------⑤ v_result := '입력 완료!!'; end if; EXCEPTION -------------⑥ WHEN OTHERS THEN ROLLBACK; v_result := 'ERROR 발생'; END; /
[예제] SQL Server CREATE Procedure dbo.p_DEPT_insert -------------① @v_DEPTNO int, @v_dname varchar(30), @v_loc varchar(30), @v_result varchar(100) OUTPUT AS DECLARE @cnt int SET @cnt = 0 BEGIN SELECT @cnt=COUNT(*) -------------② FROM DEPT WHERE DEPTNO = @v_DEPTNO IF @cnt > 0 -------------③ BEGIN SET @v_result = '이미 등록된 부서번호이다' RETURN END ELSE BEGIN BEGIN TRAN INSERT INTO DEPT (DEPTNO, DNAME, LOC) -------------④ VALUES (@v_DEPTNO, @v_dname, @v_loc) IF @@ERROR<>0 BEGIN ROLLBACK -------------⑥ SET @v_result = 'ERROR 발생' RETURN END ELSE BEGIN COMMIT -------------⑤ SET @v_result = '입력 완료!!' RETURN END END END
DEPT 테이블은 DEPTNO 칼럼이 PRIMARY KEY로 설정되어 있으므로, DEPTNO 칼럼에는 유일한 값을 넣어야만 한다. [예제]에 대한 설명은 다음과 같다.
① DEPT 테이블에 들어갈 칼럼 값(부서코드, 부서명, 위치)을 입력 받는다. ② 입력 받은 부서코드가 존재하는지 확인한다. ③ 부서코드가 존재하면 '이미 등록된 부서번호입니다'라는 메시지를 출력 값에 넣는다. ④ 부서코드가 존재하지 않으면 입력받은 필드 값으로 새로운 부서 레코드를 입력한다. ⑤ 새로운 부서가 정상적으로 입력됐을 경우에는 COMMIT 명령어를 통해서 트랜잭션을 종료한다. ⑥ 에러가 발생하면 모든 트랜잭션을 취소하고 'ERROR 발생'라는 메시지를 출력값에 넣는다.
앞에 있는 프로시저를 작성하면서 주의해야 할 몇 가지 문법적 요소가 있다. 첫째, PL/SQL 및 T-SQL에서는 다양한 변수가 있다. 예제에서 나온 cnt라는 변수를 SCALAR 변수라고 한다. SCALAR 변수는 사용자의 임시 데이터를 하나만 저장할 수 있는 변수이며 거의 모든 형태의 데이터 유형을 지정할 수 있다. 둘째, PL/SQL에서 사용하는 SQL 구문은 대부분 지금까지 살펴본 것과 동일하게 사용할 수 있지만 SELECT 문장은 다르다. PL/SQL에서 사용하는 SELECT 문장은 결과값이 반드시 있어야 하며, 그 결과 역시 반드시 하나여야 한다. 조회 결과가 없거나 하나 이상인 경우에는 에러를 발생시킨다. T-SQL에서는 결과 값이 없어도 에러가 발생하지 않는다. 셋째, T-SQL을 비롯하여 일반적으로 대입 연산자는 “=”을 사용하지만 PL/SQL에서는 “:=”를 사용한다. 넷째, 에러 처리를 담당하는 EXCEPTION에는 WHEN ~ THEN 절을 사용하여 에러의 종류별로 적절히 처리한다. OTHERS를 이용하여 모든 에러를 처리할 수 있지만 정확하게 에러를 처리하는 것이 좋다. T-SQL에서는 에러 처리를 다양하게 처리할 수 있으며 위의 예제는 그 한 예이다. 다음은 지금까지 작성한 프로시저를 실행하여 기능을 테스트한 과정이다.
[실행 결과] Oracle SQL> SELECT * FROM DEPT; -----------------① DEPTNO DNAME LOC ------- ------- --------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON SQL> variable rslt varchar2(30); -----------------② SQL> EXECUTE p_DEPT_insert(10,'dev','seoul',:rslt); -----------------③ PL/SQL 처리가 정상적으로 완료되었다. SQL> print rslt; -----------------④ RSLT -------------------------------- 이미 등록된 부서번호이다 SQL> EXECUTE p_DEPT_insert(50,'NewDev','seoul',:rslt); ----------------⑤ PL/SQL 처리가 정상적으로 완료되었다. SQL> print rslt; ----------------⑥ RSLT -------------------------------- 입력 완료!! SQL> SELECT * FROM DEPT; ----------------⑦ DEPTNO DNAME LOC ------ -------- --------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON 50 NewDev SEOUL 5개의 행이 선택되었다.
① DEPT 테이블을 조회하면 총 4개 행의 결과가 출력된다. ② Procedure를 실행한 결과 값을 받을 변수를 선언한다. (BIND 변수) ③ 존재하는 DEPTNO(10)를 가지고 Procedure를 실행한다. ④ DEPTNO가 10인 부서는 이미 존재하기 때문에 변수 rslt를 print해 보면 '이미 등록된 부서번호이다' 라고 출력된다. ⑤ 이번에는 새로운 DEPTNO(50)를 가지고 입력한다. ⑥ rslt를 출력해 보면 '입력 완료!!' 라고 출력된다. ⑦ DEPT 테이블을 조회하여 보면 DEPTNO가 50인 데이터가 정확하게 저장되었음을 확인할 수 있다.
T-SQL로 작성한 프로시저를 실행하기 위해서는 일반적으로 SQL Server에서 제공하는 기본 클라이언트 프로그램인 SQL Server MANAGEMENT STUDIO를 사용한다.
[실행 결과] SQL Server SELECT * FROM DEPT; -----------------① DEPTNO DNAME LOC ------- ---------- --------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON DECALRE @v_result VARCHAR(100) -----------------② EXECUTE dbo.p_DEPT_insert 10, 'dev', 'seoul', @v_result=@v_result OUTPUT -----------------③ SELECT @v_result AS RSLT -----------------④ RSLT -------------------------------- 이미 등록된 부서번호이다 DECALRE @v_result VARCHAR(100) -----------------⑤ EXECUTE dbo.p_DEPT_insert 50, 'dev', 'seoul', @v_result=@v_result OUTPUT -----------------⑥ SELECT @v_result AS RSLT -----------------⑦ RSLT -------------------------------- 입력 완료! SELECT * FROM DEPT; ----------------⑧ DEPTNO DNAME LOC ------- -------- --------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON 50 NewDev SEOUL 5개의 행에서 선택되었다.
① DEPT 테이블을 조회하면 총 4개 행의 결과가 출력된다. ② Procedure를 실행한 결과 값을 받을 변수를 선언한다. ③ 존재하는 DEPTNO(10)를 가지고 Procedure를 실행한다. ④ DEPTNO가 10인 부서는 이미 존재하기 때문에 변수 rslt를 print해 보면 ‘이미 등록된 부서번호이다’라고 출력된다. ⑤ Procedure를 실행한 결과 값을 받을 변수를 선언한다. ⑥ 이번에는 새로운 DEPTNO(50)를 가지고 입력한다. ⑦ rslt를 출력해 보면 ‘입력 완료!’라고 출력된다. ⑧ DEPT 테이블을 조회하여 보면 DEPTNO가 50인 데이터가 정확하게 저장되었음을 확인할 수 있다.
5. User Defined Function의 생성과 활용
User Defined Function은 Procedure처럼 절차형 SQL을 로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합을 의미한다. 앞에서 학습한 SUM, SUBSTR, NVL 등의 함수는 벤더에서 미리 만들어둔 내장 함수이고, 사용자가 별도의 함수를 만들 수도 있다. Function이 Procedure와 다른 점은 RETURN을 사용해서 하나의 값을 반드시 되돌려 줘야 한다는 것이다. 즉 Function은 Procedure와는 달리 SQL 문장에서 특정 작업을
[예제] K-리그 8월 경기결과와 두 팀간의 점수차를 ABS 함수를 사용하여 절대값으로 출력한다.
[예제] Oracle SELECT SCHE_DATE 경기일자, HOMETEAM_ID || ' - ' || AWAYTEAM_ID 팀들, HOME_SCORE || ' - ' || AWAY_SCORE SCORE, ABS(HOME_SCORE - AWAY_SCORE) 점수차 FROM SCHEDULE WHERE GUBUN = 'Y' AND SCHE_DATE BETWEEN '20120801' AND '20120831' ORDER BY SCHE_DATE;
[예제] SQL Server SELECT SCHE_DATE 경기일자, HOMETEAM_ID + ' - ' + AWAYTEAM_ID AS 팀들, HOME_SCORE + ' - ' + AWAY_SCORE AS SCORE, ABS(HOME_SCORE - AWAY_SCORE) AS 점수차 FROM SCHEDULE WHERE GUBUN = 'Y' AND SCHE_DATE BETWEEN '20120801' AND '20120831' ORDER BY SCHE_DATE;
[실행 결과] 경기일자 팀들 SCORE 점수차 ------- -------- ----- ----- 20120803 K01 - K03 3 - 0 3 20120803 K06 - K09 2 - 1 1 20120803 K08 - K07 1 - 0 1 20120804 K05 - K04 2 - 1 1 20120804 K10 - K02 0 - 3 3 20120811 K07 - K10 1 - 1 0 20120811 K03 - K08 2 - 0 2 20120811 K09 - K05 0 - 1 1 20120811 K04 - K02 0 - 2 2 20120811 K01 - K06 0 - 0 0 20120818 K05 - K01 0 - 2 2 20120818 K02 - K09 1 - 2 1 20120818 K08 - K10 3 - 1 2 20120818 K04 - K07 1 - 0 1 20120818 K06 - K03 3 - 1 2 20120824 K02 - K01 1 - 1 0 20120824 K05 - K03 3 - 3 0 20120824 K08 - K06 4 - 3 1 20120825 K10 - K04 1 - 1 0 20120825 K09 - K07 1 - 1 0 20120828 K04 - K08 2 - 3 1 20120828 K09 - K10 2 - 0 2 20120828 K03 - K02 0 - 0 0 20120828 K01 - K07 0 - 1 1 20120828 K06 - K05 1 - 1 0 25개의 행이 선택되었다.
[예제]에서 사용한 ABS 함수를 만드는데, INPUT 값으로 숫자만 들어온다고 가정한다.
[예제] Oracle CREATE OR REPLACE Function UTIL_ABS (v_input in number) ---------------- ① return NUMBER IS v_return number := 0; ---------------- ② BEGIN if v_input < 0 then ---------------- ③ v_return := v_input * -1; else v_return := v_input; end if; RETURN v_return; ---------------- ④ END; /
[예제] SQL Server CREATE Function dbo.UTIL_ABS (@v_input int) ---------------- ① RETURNS int AS BEGIN DECLARE @v_return int ---------------- ② SET @v_return=0 IF @v_input < 0 ---------------- ③ SET @v_return = @v_input * -1 ELSE SET @v_return = @v_input RETURN @v_return; ---------------- ④ END
[예제]에서 생성한 UTIL_ABS Function의 처리 과정은 다음과 같다.
① 숫자 값을 입력 받는다. 예제에서는 숫자 값만 입력된다고 가정한다. ② 리턴 값을 받아 줄 변수인 v_return를 선언한다. ③ 입력 값이 음수이면 -1을 곱하여 v_return 변수에 대입한다. ④ v_return 변수를 리턴한다.
[예제] 함수를 이용하여 앞의 SQL을 수정하여 실행한다.
[예제] Oracle SELECT SCHE_DATE 경기일자, HOMETEAM_ID || ' - ' || AWAYTEAM_ID 팀들, HOME_SCORE || ' - ' || AWAY_SCORE SCORE, UTIL_ABS(HOME_SCORE - AWAY_SCORE) 점수차 FROM SCHEDULE WHERE GUBUN = 'Y' AND SCHE_DATE BETWEEN '20120801' AND '20120831' ORDER BY SCHE_DATE;
[예제] SQL Server SELECT SCHE_DATE 경기일자, HOMETEAM_ID + ' - ' + AWAYTEAM_ID AS 팀들, HOME_SCORE + ' - ' + AWAY_SCORE AS SCORE, dbo.UTIL_ABS(HOME_SCORE - AWAY_SCORE) AS 점수차 FROM SCHEDULE WHERE GUBUN = 'Y' AND SCHE_DATE BETWEEN '20120801' AND '20120831' ORDER BY SCHE_DATE;
[실행 결과] 경기일자 팀들 SCORE 점수차 ------- -------- ------ ------ 20120803 K01 - K03 3 - 0 3 20120803 K06 - K09 2 - 1 1 20120803 K08 - K07 1 - 0 1 20120804 K05 - K04 2 - 1 1 20120804 K10 - K02 0 - 3 3 25개의 행이 선택되었다.
실행 결과는 앞의 ABS 내장함수를 사용한 SQL 문장과 같은 결과를 확인할 수 있다.
6. Trigger의 생성과 활용
Trigger란 특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램이다. 즉 사용자가 직접 호출하여 사용하는 것이 아니고 데이터베이스에서 자동적으로 수행하게 된다. Trigger는 테이블과 뷰, 데이터베이스 작업을 대상으로 정의할 수 있으며, 전체 트랜잭션 작업에 대해 발생되는 Trigger와 각 행에 대해서 발생되는 Trigger가 있다. 요구 사항은 다음과 같다고 가정한다. 어떤 쇼핑몰에 하루에 수만 건의 주문이 들어온다. 주문 데이터는 주문일자, 주문상품, 수량, 가격이 있으며, 사장을 비롯한 모든 임직원이 일자별, 상품별 총 판매수량과 총 판매가격으로 구성된 주문 실적을 온라인상으로 실시간 조회한다고 했을 때, 한 사람의 임직원이 조회할 때마다 수만 건의 데이터를 읽어 계산해야 한다. 가끔 한 번씩 조회한다면 문제가 없을 수도 있으나 빈번하게 조회작업이 일어난다면 조회작업에 많은 시간을 허비할 수 있다.
[예제] 트리거(Trigger)를 사용하여 주문한 건이 입력될 때마다, 일자별 상품별로 판매수량과 판매금액을 집계하여 집계자료를 보관하도록 한다. 먼저 관련 테이블을 생성한다.

[예제] Oracle CREATE TABLE ORDER_LIST ( ORDER_DATE CHAR(8) NOT NULL, PRODUCT VARCHAR2(10) NOT NULL, QTY NUMBER NOT NULL, AMOUNT NUMBER NOT NULL); CREATE TABLE SALES_PER_DATE ( SALE_DATE CHAR(8) NOT NULL, PRODUCT VARCHAR2(10) NOT NULL, QTY NUMBER NOT NULL, AMOUNT NUMBER NOT NULL);
[예제] SQL Server CREATE TABLE ORDER_LIST ( ORDER_DATE CHAR(8) NOT NULL, PRODUCT VARCHAR(10) NOT NULL, QTY INT NOT NULL, AMOUNT INT NOT NULL); CREATE TABLE SALES_PER_DATE ( SALE_DATE CHAR(8) NOT NULL, PRODUCT VARCHAR(10) NOT NULL, QTY INT NOT NULL, AMOUNT INT NOT NULL);
[예제] 이제 Trigger를 작성한다. Trigger의 역할은 ORDER_LIST에 주문 정보가 입력되면 주문 정보의 주문 일자(ORDER_LIST.ORDER_DATE)와 주문 상품(ORDER_LIST.PRODUCT)을 기준으로 판매 집계 테이블(SALES_PER_DATE)에 해당 주문 일자의 주문 상품 레코드가 존재하면 판매 수량과 판매 금액을 더하고 존재하지 않으면 새로운 레코드를 입력한다.
[예제] Oracle CREATE OR REPLACE Trigger SUMMARY_SALES ---------------- ① AFTER INSERT ON ORDER_LIST FOR EACH ROW DECLARE ---------------- ② o_date ORDER_LIST.order_date%TYPE; o_prod ORDER_LIST.product%TYPE; BEGIN o_date := :NEW.order_date; o_prod := :NEW.product; UPDATE SALES_PER_DATE ---------------- ③ SET qty = qty + :NEW.qty, amount = amount + :NEW.amount WHERE sale_date = o_date AND product = o_prod; if SQL%NOTFOUND then ---------------- ④ INSERT INTO SALES_PER_DATE VALUES(o_date, o_prod, :NEW.qty, :NEW.amount); end if; END; /
SUMMARY_SALES Trigger의 처리절차를 설명하면 다음과 같다.
① Trigger를 선언한다.CREATE OR REPLACE Trigger SUMMARY_SALES : Trigger 선언문AFTER INSERT : 레코드가 입력이 된 후 Trigger 발생 ON ORDER_LIST : ORDER_LIST 테이블에 Trigger 설정FOR EACH ROW : 각 ROW마다 Trigger 적용 ② o_date(주문일자), o_prod(주문상품) 값을 저장할 변수를 선언하고, 신규로 입력된 데이터를 저장한다. : NEW는 신규로 입력된 레코드의 정보를 가지고 있는 구조체 : OLD는 수정, 삭제되기 전의 레코드를 가지고 있는 구조체 [표 Ⅱ-2-17] 참조 ③ 먼저 입력된 주문 내역의 주문 일자와 주문 상품을 기준으로 SALES_PER_DATE 테이블에 업데이트한다. ④처리 결과가 SQL%NOTFOUND이면 해당 주문 일자의 주문 상품 실적이 존재하지 않으며, SALES_ PER_DATE 테이블에 새로운 집계 데이터를 입력한다.

[예제] SQL Server CREATE Trigger dbo.SUMMARY_SALES ---------------- ① ON ORDER_LIST AFTER INSERT AS DECLARE @o_date DATETIME,@o_prod INT,@qty int, @amount int BEGIN SELECT @o_date=order_date, @o_prod=product, @qty=qty, @amount=amount FROM inserted ---------------- ② UPDATE SALES_PER_DATE ---------------- ③ SET qty = qty + @qty, amount = amount + @amount WHERE sale_date = @o_date AND product = @o_prod; IF @@ROWCOUNT=0 ---------------- ④ INSERT INTO SALES_PER_DATE VALUES(@o_date, @o_prod, @qty, @amount) END
SUMMARY_SALES Trigger의 처리절차를 설명하면 다음과 같다.
① Trigger를 선언한다.CREATE Trigger SUMMARY_SALES : Trigger 선언문ON ORDER_LIST : ORDER_LIST 테이블에 Trigger 설정AFTER INSERT : 레코드가 입력이 된 후 Trigger 발생 ② o_date(주문일자), o_prod(주문상품), qty(수량), amount(금액) 값을 저장할 변수를 선언하고, 신규로 입력된 데이터를 저장한다.inserted는 신규로 입력된 레코드의 정보를 가지고 있는 구조체deleted는 수정, 삭제되기 전의 레코드를 가지고 있는 구조체. [표 Ⅱ-2-18] 참조 ③ 먼저 입력된 주문 내역의 주문 일자와 주문 상품을 기준으로 SALES_PER_DATE 테이블에 업데이트한다. ④ 처리 결과가 0건이면 해당 주문 일자의 주문 상품 실적이 존재하지 않으며, SALES_PER_DATE 테이블에 새로운 집계 데이터를 입력한다.

[예제] ORDER_LIST 테이블에 주문 정보를 입력한다.
[예제] Oracle SQL> SELECT * FROM ORDER_LIST; 선택된 레코드가 없다. SQL> SELECT * FROM SALES_PER_DATE; 선택된 레코드가 없다. SQL> INSERT INTO ORDER_LIST VALUES('20120901', 'MONOPACK', 10, 300000); 1개의 행이 만들어졌다. SQL> COMMIT; 커밋이 완료되었다.
[예제] SQL Server SELECT * FROM ORDER_LIST; 선택된 레코드가 없다. SELECT * FROM SALES_PER_DATE; 선택된 레코드가 없다. INSERT INTO ORDER_LIST VALUES('20120901', 'MONOPACK', 10, 300000); 1개의 행이 만들어졌다.
[예제] 주문 정보와 판매 집?.
[실행 결과] SQL> SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT --------- -------- -------- ------- 20120901 MONOPACK 10 300000 SQL> SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- -------- -------- -------- 20120901 MONOPACK 10 300000
[예제] 다시 한 번 같은 데이터를 입력해보고, 두 테이블의 데이터를 확인한다.
[실행 결과] Oracle SQL> INSERT INTO ORDER_LIST VALUES('20120901','MONOPACK',20,600000); 1개의 행이 만들어졌다. SQL> COMMIT; 커밋이 완료되었다. SQL> SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT --------- ---------- ------ ------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 SQL> SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- --------- ----- ------- 20120901 MONOPACK 30 900000
[실행 결과] SQL Server INSERT INTO ORDER_LIST VALUES('20120901','MONOPACK',20,600000); 1개의 행이 만들어졌다. SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT --------- --------- ----- -------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- --------- ---- -------- 20120901 MONOPACK 30 900000
[예제] 이번에는 다른 상품으로 주문 데이터를 입력한 후 두 테이블의 결과를 조회해 보고 트랜잭션을 ROLLBACK 수행한다. 판매 데이터의 입력 취소가 일어나면, 주문 정보 테이블과 판매 집계 테이블에 동시에 입력(수정) 취소가 일어나는지 확인해본다.
[실행 결과] Oracle SQL> INSERT INTO ORDER_LIST VALUES('20120901','MULTIPACK',10,300000); 1개의 행이 만들어졌다. SQL> SELECT * FROM ORDER_LIST; ORDER_DA PRODUCT QTY AMOUNT -------- -------- ------ ------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 20120901 MULTIPACK 10 300000 SQL> SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- -------- ------ ------- 20120901 MONOPACK 30 900000 20120901 MULTIPACK 10 300000 SQL> ROLLBACK; 롤백이 완료되었다. SQL> SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT -------- -------- ------ ------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 SQL> SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- --------- ------ ------- 20120901 MONOPACK 30 900000
[실행 결과] SQL Server BEGIN TRAN INSERT INTO ORDER_LIST VALUES('20120901','MULTIPACK',10,300000); 1개의 행이 만들어졌다. SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT --------- --------- ------ ------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 20120901 MULTIPACK 10 300000 SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- --------- ------ ------- 20120901 MONOPACK 30 900000 20120901 MULTIPACK 10 300000 ROLLBACK; 롤백이 완료되었다. SELECT * FROM ORDER_LIST; ORDER_DATG PRODUCT QTY AMOUNT --------- -------- ------ ------- 20120901 MONOPACK 10 300000 20120901 MONOPACK 20 600000 SELECT * FROM SALES_PER_DATE; SALE_DATG PRODUCT QTY AMOUNT -------- -------- ------ ------- 20120901 MONOPACK 30 900000
ROLLBACK을 하면 하나의 트랜잭션이 취소가 되어 Trigger로 입력된 정보까지 하나의 트랜잭션으로 인식하여 두 테이블 모두 입력 취소가 되는 것을 보여 주고 있다. Trigger는 데이터베이스에 의해 자동 호출되지만 결국 INSERT, UPDATE, DELETE 문과 하나의 트랜잭션 안에서 일어나는 일련의 작업들이라 할 수 있다. Trigger는 데이터베이스 보안의 적용, 유효하지 않은 트랜잭션의 예방, 업무 규칙 자동 적용 제공 등에 사용될 수 있다.
7. 프로시저와 트리거의 차이점
프로시저는 BEGIN ~ END 절 내에 COMMIT, ROLLBACK과 같은 트랜잭션 종료 명령어를 사용할 수 있지만, 데이터베이스 트리거는 BEGIN ~ END 절 내에 사용할 수 없다.

출처 : http://www.dbguide.net/db.db?cmd=view&boardUid=148207&boardConfigUid=9&categoryUid=216&boardIdx=135&boardStep=1